Projects & Products
computational hydrology | model analysis
data dissemination | data management

Basin Fabric
Basin-Fabric is an open, extensible framework for constructing basin-based geospatial and machine-learning–ready datasets to support large-scale hydrologic modeling and prediction. The project integrates basin delineation, feature engineering, and machine-learning workflows in a reproducible and regionally extensible manner. It can be found on GitHub under basin-fabric.
Basin-Fabric was conceived, designed, and primarily implemented by me in June to July 2023 with the GitHub repository being created on July 11, 2023. This core development phase includes the overall system architecture, data structures and conventions, basin-centric processing logic, and the foundational workflows that define the Basin-Fabric concept. At that time, I was employed as a Research Scientist and Lead of the UFZ cluster at ScaDS.AI (Center for Scalable Data Analytics and Artificial Intelligence), Leipzig, Germany, in collaboration with the Helmholtz Centre for Environmental Research – UFZ who funded this work.
After joining the Department of Earth and Environmental Sciences at the University of Waterloo as a Research Associate Professor, the additional contributions to Basin-Fabric were strictly limited to the addition of new datasets and regions. No core architectural changes, conceptual redesign, or foundational methodological developments of Basin-Fabric occurred during this later period.
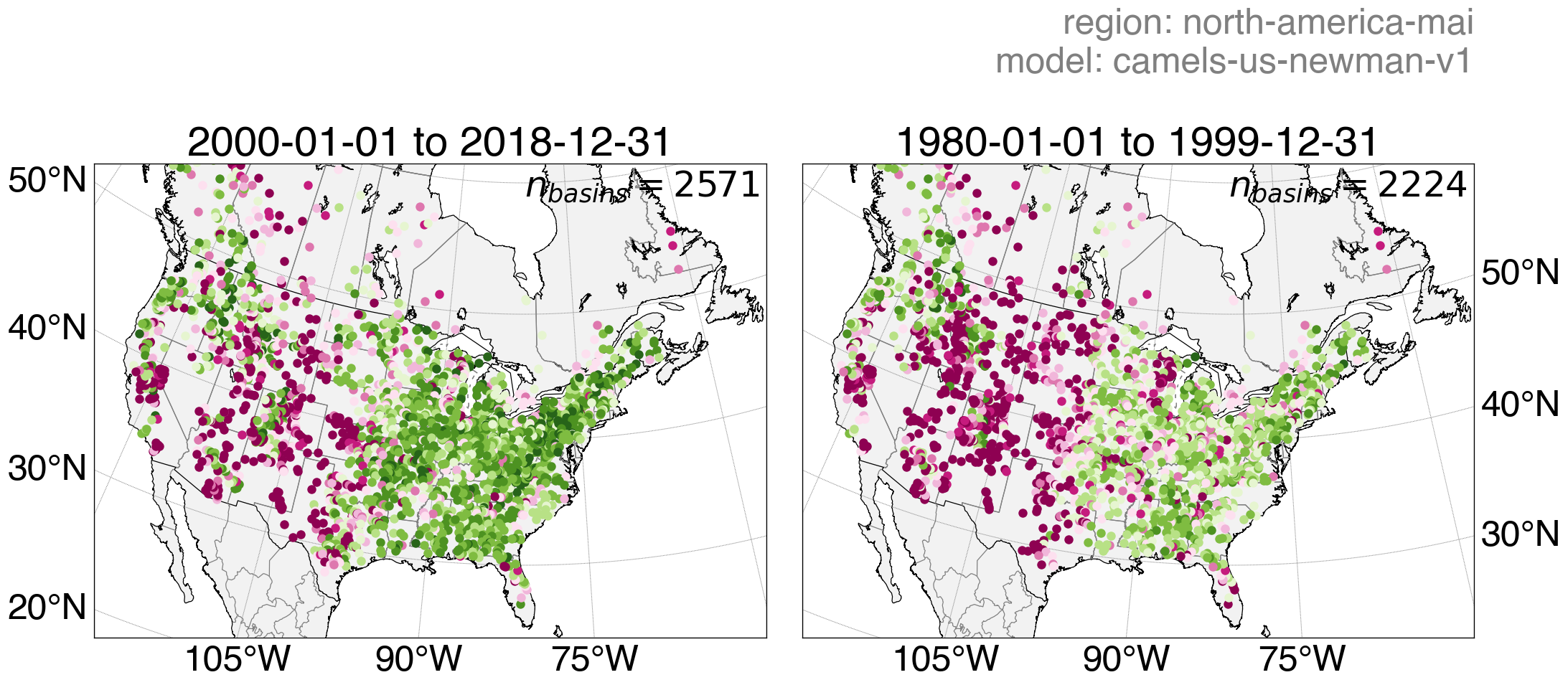

Continental-scale LSTM streamflow predictions of a model trained across CAMELS-US using Basin-Fabric.
Left: Training period. Right: Testing period.
Download PNG | Download results
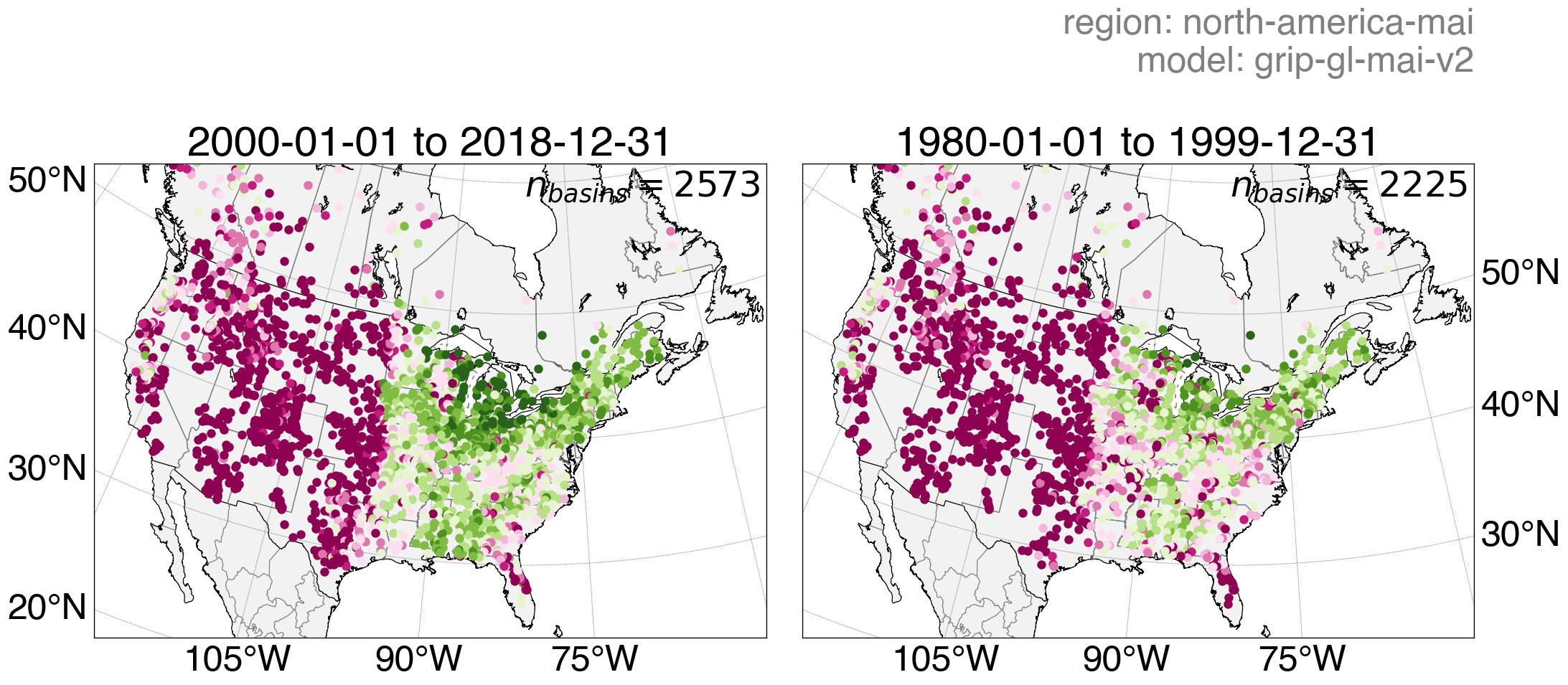
Continental-scale LSTM streamflow predictions of a model trained across the Great Lakes (GRIP-GL) using Basin-Fabric.
Left: Training period. Right: Testing period.
Download PNG | Download results
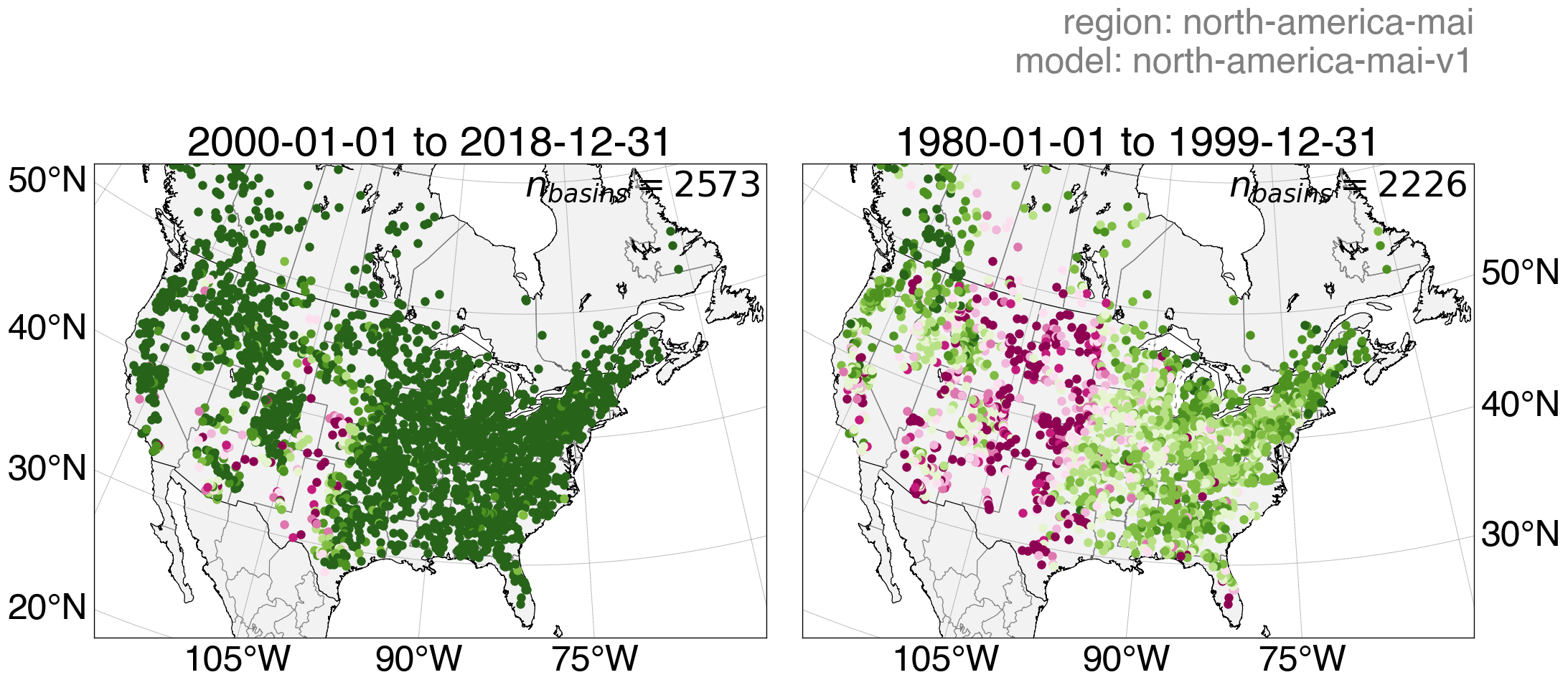
Continental-scale LSTM streamflow predictions of a model trained across North America using Basin-Fabric.
Left: Training period. Right: Testing period.
Download PNG | Download results
Basin-Fabric contains forcing data, basin characteristics, and training data for process-based and data-driven model development aside from workflows on training LSTM models specifically. Results and maps are provided for LSTMS build and used to generate streamflow predictions across the various regions.
The data and results are yours to explore and use with proper attribution of my contributions.
Resources:
Basin-Fabric:
codes
regions
w/ shapefiles, observations,
predictions, and more
input datasets
Blended model
A model is called blended when instead of choosing one specific process implementation for a process (e.g., infiltration as used in HBV) the weighted average of several options (e.g., infiltration used in HBV, HMETS, and VIC) is used. The weights are the (additional) parameters that describe the structure of the blended model. After model calibration, a large weight indicates that the corresponding process option is more suitable compared to others. The first blended model was introduced by Mai et al. (2020) using the Raven modeling framework.
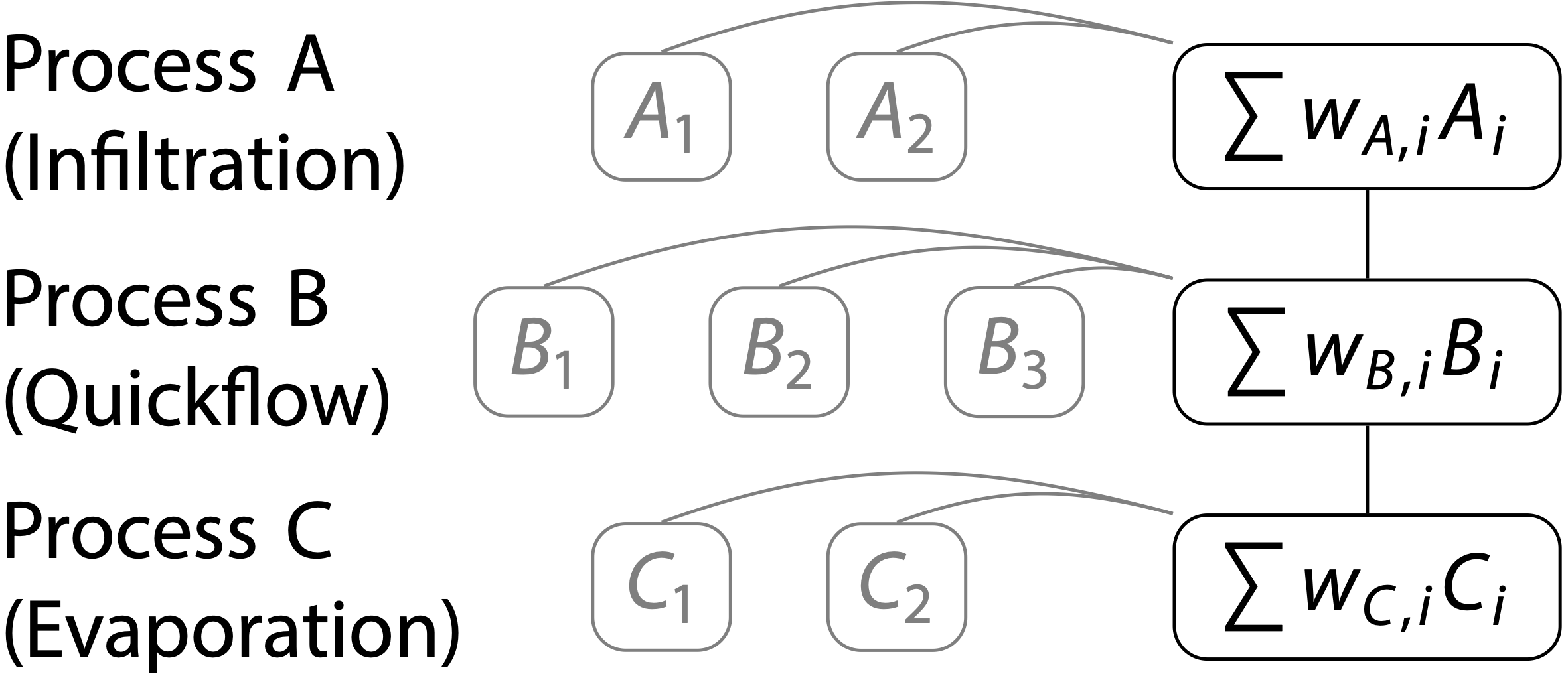
Since blended model structures parameterize not only the processes through the model parameters but also the model structure through the weights, it allows to simultaneously analyse parameters and structure.
Mai et al. (2020) introduced the extended Sobol’ Sensitivity Analysis (xSSA) that used a blended model structure to derive sensitivities of model parameters, process options and entire processes.
Chlumsky et al. (2021) then used a blended model to demonstrate that calibrating such blended models leads to more robust results compared to calibrating all possible model combinations while being computationally much more efficient.
Resources:
Introduction blended model:
Publication |
data & codes |
wiki
Simultaneous sensitivity analysis
of model structure and parameters
(introduction):
Publication |
data & codes |
wiki
Simultaneous calibration of model
structure and parameters:
Publication |
data & codes
Sensitivity analysis over North America
Streamflow sensitivity to different hydrologic processes varies in both space and time. This sensitivity is traditionally evaluated for the parameters specific to a given hydrologic model simulating streamflow.
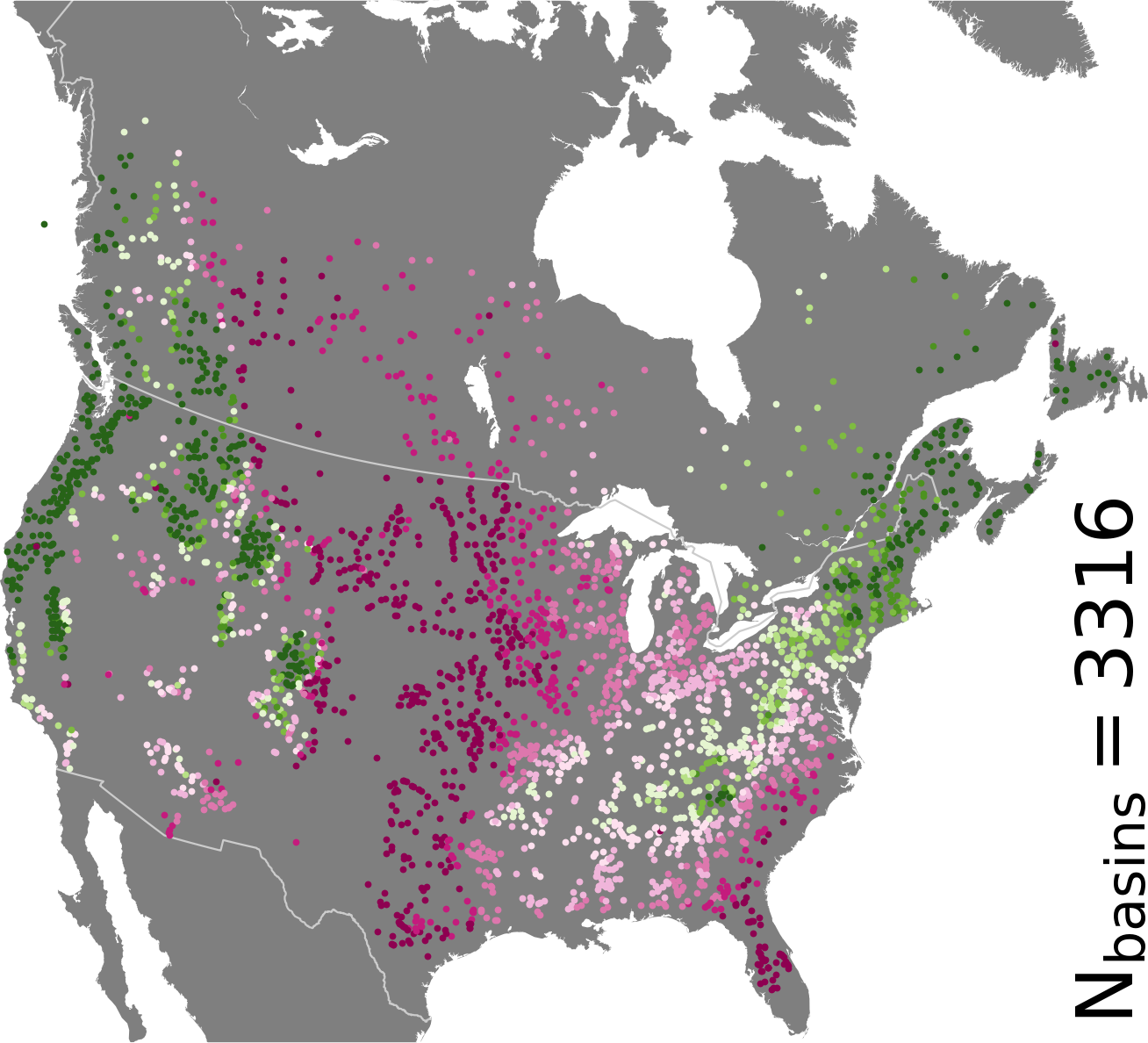
Mai et al. (2022) applied a novel analysis (xSSA) over more than 3000 basins across North America considering a blended hydrologic model structure, which includes not only parametric, but also structural uncertainties.
This enables seamless quantification of model process sensitivities and parameter sensitivities across a continuous set of models. It also leads to high-level conclusions about the importance of water cycle components on streamflow predictions, such as quickflow being the most sensitive process for streamflow simulations across the North American continent.
The results of the 3000 basins are used to derive an approximation of sensitivities based on physiographic and climatologic data without the need to perform expensive sensitivity analyses.
Detailed spatio-temporal inputs and results are shared through an interactive website.
Resources:
HydroHub
The HydroHub portal is meant to distribute data, model setups, and results of various large-scale hydrologic studies and beyond. It aims to ease data discovery and facilitate environmental research. The main focus however is to create an engaging platform for end-users.
HydroHub is currently hosting the results of a sensitivity analysis over North America as well as the results of a model intercomparison study over the Great Lakes. The websites are customized for each project to maximize the user engagement through real-time analysis and visualization.
Resources:
GRIP-E and GRIP-GL
The Great Lakes Runoff Intercomparison Project (GRIP) for Lake Erie (GRIP-E) and its extension to the entire Great Lakes (GRIP-GL) were funded through the Integrated Modeling Program for Canada (IMPC) within the Global Water Futures (GWF) program between 2018 and 2022.

These two projects compare a wide range of lumped, distributed, and data-driven models that are used operationally and/or for research purposes across Canada, the United States, and Europe. The models include GR4J, LBRM, HMETS, HYMOD2, GEM-Hydro, MESH-SVS, MESH-CLASS, VIC, SWAT, WATFLOOD, HYPE, mHM, LSTM, and more.
While GRIP-E focused only on streamflow, GRIP-GL compared model performance for streamflow and additional types of reference datasets (AET, SSM, SWE).
In GRIP-E modelers were asked to use the same meteorologic forcings to provide model results at a pre-defined set locations while GRIP-GL used a standardized set of all inputs (forcings, routing, geophysical datasets) to allow for conclusions to be drawn independent of data used to run the models.
CaSPAr
The Canadian Surface Prediction Archive (CaSPAr) is an archive of numerical weather predictions issued by Environment and Climate Change Canada.
CaSPAr started archiving in May 2017 and is accessible online since June 2018. It is free of charge and archives eleven operational NWPs, three pre-operational product and three reanalysis dataset that are all generated by ECCC at an hourly to daily temporal resolution and 2.5 km to 50 km spatial resolution. To date (Oct 26, 2022), the archive contains 887 TB of data while 326 GB of new data are added every night (9.9 TB added per month).
The automatic user request functionality is operational since June 2018 and allows users to precisely request data according to their needs, i.e., spatial cropping based on a standard shape or uploaded shapefile of the domain of interest, selection of forecast horizons, variables as well as issue dates. The degree of customization in CaSPAr is a unique feature relative to other publicly accessible numerical weather prediction archives and it minimizes user download requirements and local processing time.
The data requested by a user are processed on the backend and the user is notified by email with a link to download the data. The download is realized using Globus that allows for secure and fast, parallel data transfers that is free of charge for the users.
Resources:
Historical Flood Event Python toolkit
This library is a collection of tools to analyse flood events of the Historical Flood Event (HFE) Database issued by Natural Resources Canada (NRCan).
The tools comprise scripts to (a) retrieve, standardize, read, and plot precipitation data from CaSPAr and GeoMet for the flood events available in the database, (b) identify the time period and bounding box to analyse a given event, (c) interpolate the gridded precipitation data to stations, and (d) identify major precipitation events that caused the flood events.
The HFE database contains two types of records: single-point flood occurrences and multi-point flood events. Workflow scripts are provided in the toolkit to analyse each of these kinds of records producing a predefined set of plots, animated images, and statistics of the precipitation causing the recorded event.
A detailed documentation of the tools and their usage is provided as well as instructions on how to setup a Python environment with requirements of the toolkit. Build-in Python tests ensure that the integrity of the toolkit is maintained even with future implementations and additions to the toolkit.
Ostrich
The Optimization Software Toolkit for Research Involving Computational Heuristics (OSTRICH) is a model-independent program that automates the processes of model calibration and design optimization without requiring the user to write any additional software. Typically, users only need to fill out a few required portions of the OSTRICH input file (i.e., ostIn.txt) and create template model input files.

OSTRICH has been developed by developed by L. Shawn Matott (University of Buffalo) and is maintained by him, Drew Loney (U.S. Bureau of Reclamation), and Julie Mai (University of Waterloo).
The following material has been compiled to serve as an OSTRICH crash course. The material includes slides and four exercises of increasing complexity and difficulty. More general OSTRICH resources are provided below under "Resources".
The course material has been usually used for the calibration part of the "Principles of Hydrologic Modeling" course at the University of Waterloo (James Craig, Bryan Tolson, Juliane Mai).
There are four exercise practice sheets available:
DDS (single objective) in sequential mode
PADDS (multi objective) in sequential mode
DDS (single objective) in parallel mode
PADDS (multi objective) in parallel mode
The full course material including documentation for RAVEN and OSTRICH and all executables and model setups can be also downloaded ( .zip). The slides of the crash course are available for download as well ( .pdf).
Resources:
EEE
The Efficient Elementary Effects (EEE) method is a sequential screening approach based on the Morris method that fully automatically distinguishes informative parameters from noninformative ones using a minimal number of model runs.
The number of model runs required for a screening is usually around 10 times the number of model parameters. The model converges itself and has no algorithmic parameters. The method has been published by Cuntz et al. (2015).
The source code of EEE is available on GitHub. The associated Wiki pages includes step-by-step examples of how to employ EEE for a model. It also contains a documentation of how to add a model that is not currently provided as an example model.